
A visual navigation system that is robust to changes in scene appearance and content over time, without a need for continuous updating its map database.
THE CHALLENGE
Visual navigation is an important but challenging requirement for many applications, because the real world is dynamic with lots of moving platforms and scene changes. Our goal is to overcome the limitations of current appearance-based navigation systems, that require to update the map database to cover the range of illumination and weather conditions in their operating environments.
THE SOLUTION
SRI incorporates high-level semantic information (recognition of objects and scene layouts), learned and derived from deep learning techniques, into current appearance-based visual navigation systems (that rely on matching low-level scene features). SRI utilizes semantic information to associate visual information for improved accuracy, efficiency and robustness in our state-of-the-art navigation systems.
Vision-based navigation in large-scale unstructured environments is an important and challenging requirement for many applications. Traditional approaches rely on a highly accurate visual feature map that is built beforehand or constructed using simultaneous localization and mapping (SLAM) algorithms during navigation. However, the real world is very dynamic with lots of moving platforms and continuous scene changes. The navigation system needs to be adaptive to large appearance changes across weather, time and illumination variations. Therefore, prior maps need to be continuously updated, which is difficult and time consuming.
SRI proposes a new approach to this problem: We utilize both semantic-inference and metric-inference for our vision-based navigation system. Compared to low-level appearance features, semantic information (such as objects and scene layouts) is more robust to scene changes over time and can be matched across time. It also enables natural language interaction between humans and mobile platforms.

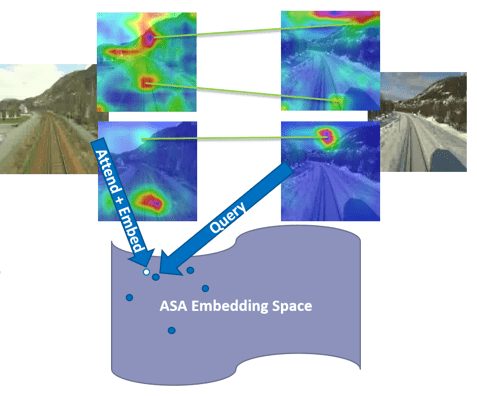
SRI has developed various methods to incorporate semantic information to improve navigation performance. For example, using mapped landmark from permanent semantic classes is able to improve overall navigation accuracy between 8%~20% while reducing 30%~50% of storage. SRI also developed a novel 2D image-based localization (2D-VL) method that estimatesposition for a given monocular query image by matching to a database of images of known locations. Our 2D-VL method fuses both appearance and semantic information using deep embedding space, and trains self-attention modules to encourage our model to focus on semantically consistent spatial regions across extreme changes in viewing conditions. It outperforms state-of-the-art methods by 19% accuracy based on standardized data sets. We expect to make further improvements and extend its use to new applications.


