Citation
Haochen Wu, Pedro Sequeira, David V. Pynadath; Proceedings of the 22nd International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2023).
Abstract
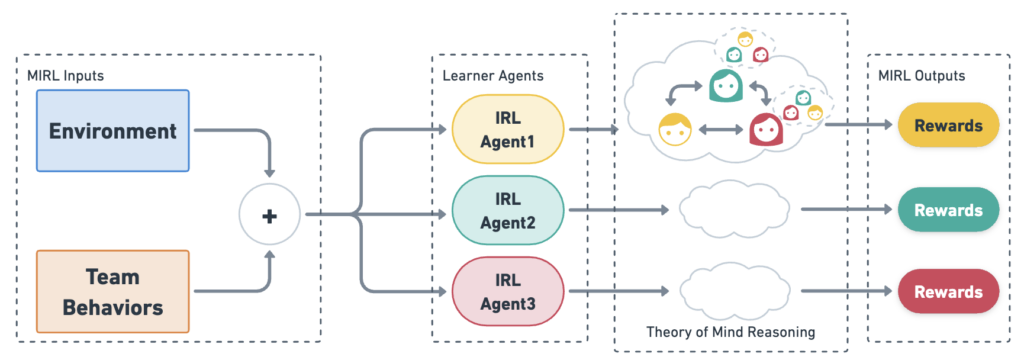
We approach the problem of understanding how people interact with each other in collaborative settings, especially when individuals know little about their teammates, via Multiagent Inverse Reinforcement Learning (MIRL), where the goal is to infer the reward functions guiding the behavior of each individual given trajectories of a team’s behavior during some task. Unlike current MIRL approaches, we do not assume that team members know each other’s goals a priori; rather, that they collaborate by adapting to the goals of others perceived by observing their behavior, all while jointly performing a task. To address this problem, we propose a novel approach to MIRL via Theory of Mind (MIRL-ToM). For each agent, we first use ToM reasoning to estimate a posterior distribution over baseline reward profiles given their demonstrated behavior. We then perform MIRL via decentralized equilibrium by employing single-agent Maximum Entropy IRL to infer a reward function for each agent, where we simulate the behavior of other teammates according to the time-varying distribution over profiles. We evaluate our approach in a simulated 2-player search-and-rescue operation where the goal of the agents, playing different roles, is to search for and evacuate victims in the environment. Our results show that the choice of baseline profiles is paramount to the recovery of the ground-truth rewards, and that MIRL-ToM is able to recover the rewards used by agents interacting both with known and unknown teammates.