Collaborative human robot autonomy
The world is rapidly integrating autonomy into vehicles, drones, and other robotic platforms, resulting in an increased demand for autonomous platforms that cooperate with one another and with humans to achieve more complex tasks. CVT is developing core methods for different multi-machine, multi-human systems across numerous DARPA, commercial, and IRAD programs.
Enhancing human-machine synergy
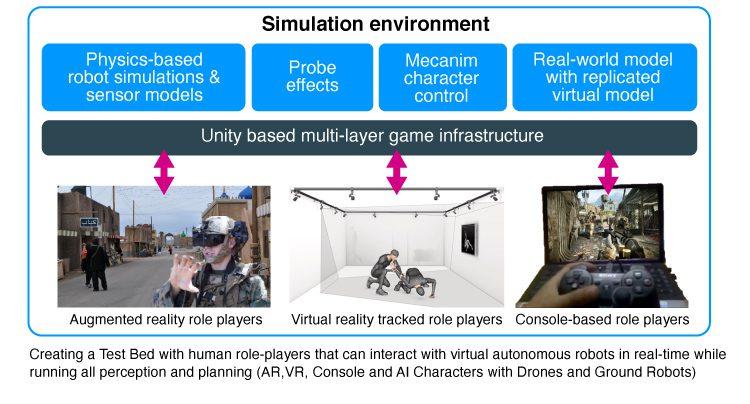
Human-robot collaboration testbeds
Developing multi-machine, multi-human systems require robust and safe methods of real-time testing in realistic environments. CVT has developed a testbed that allows multiple human players using augmented reality, virtual reality, or game consoles to interact with multiple real or virtual robotic platforms while running autonomy and perception stacks in real-time. This allows new algorithms to be tested within highly dynamic and changing environments without compromising safety.
Vision and language navigation (VLN)
VLN requires an autonomous robot to follow natural language instructions in unseen environments. Existing learning-based methods struggle with this as they focus mostly on raw visual observation and lack the semantic reasoning capabilities that are crucial in generalizing to new environments. To overcome these limitations, CVT creates a temporal memory by building a dynamic semantic map and performs cross-modal grounding to align map and language modalities, enabling more effective VLN results.
Collaboration across multiple robot platforms
CVT has developed a framework to enable multiple drones to collaborate with a ground-based moving unit to perform coordinated actions. For example, aerial platforms can rapidly surveil the wider area around the moving platform, detecting and responding to threats and coordinating actions across air and ground assets. CVT has been developing novel exploration planners that support such systems in real-time. CVT has also been developing augmented reality interfaces to simultaneously visualize and understand the common operating picture (COP) across these platforms.

Multi-robot and multi-human collaborative planning
Effective and efficient planning for teams of robots and humans towards a desired goal requires the ability to adapt and respond smoothly and collaboratively to dynamic situations. CVT created novel human-machine collaborative planning capabilities by extracting and using semantic information to enable advanced interaction and robot autonomy.
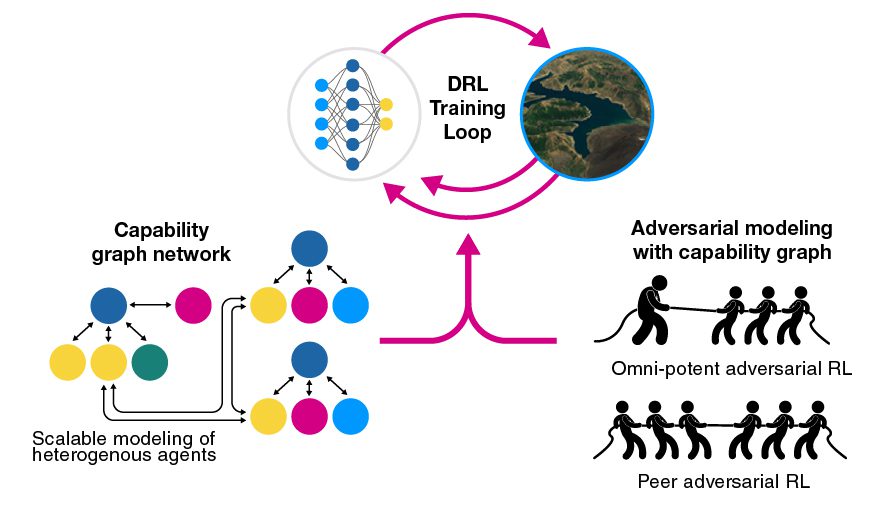
Learning policies for heterogeneous swarms working against adversaries
CVT is developing methods in which a heterogeneous group of robots can interact with humans on the battlefield when engaged in combat. CVT has developed an adversarial deep reinforcement-based architecture in which a heterogeneous swarm can go against an adversary in zero-sum games to learn policies for both teams. At test time, operators can pick either team to run autonomously and play against human-led adversaries or other autonomous systems.
Guiding autonomy policies from documents and doctrinal guidelines
Current simulated war-game construct involves numerous operators and commanders. Platforms and entities in play are predominately static and reactionary, and humans are required to adapt to adversary tactics. CVT is developing artificial intelligence-based software to automate adversary strategy, tactics, and execution, thereby augmenting, or replacing conventionally manned war-game constructs. SRI’s artificial intelligence algorithms generate models of adversary behavior, a process that is grounded in written doctrines to capture the adversary style of combat. Explicit domain knowledge acquired via machine learning is organized into hierarchical structures that fully specify the adversary’s courses of action. Implicit domain knowledge is obtained by training deep neural networks at the lowest level of the hierarchy for deep reinforcement learning-based policies.
Recent work
-

Designing better human-machine teams
SRI is discovering how AI can organize humans and machines into complex, collaborative, high-functioning units.
-

Robot teams that talk to humans
SRI scientists created a new AI-based approach to robotics that enables mobile robots to effectively communicate with each other — and with their human operators.
-
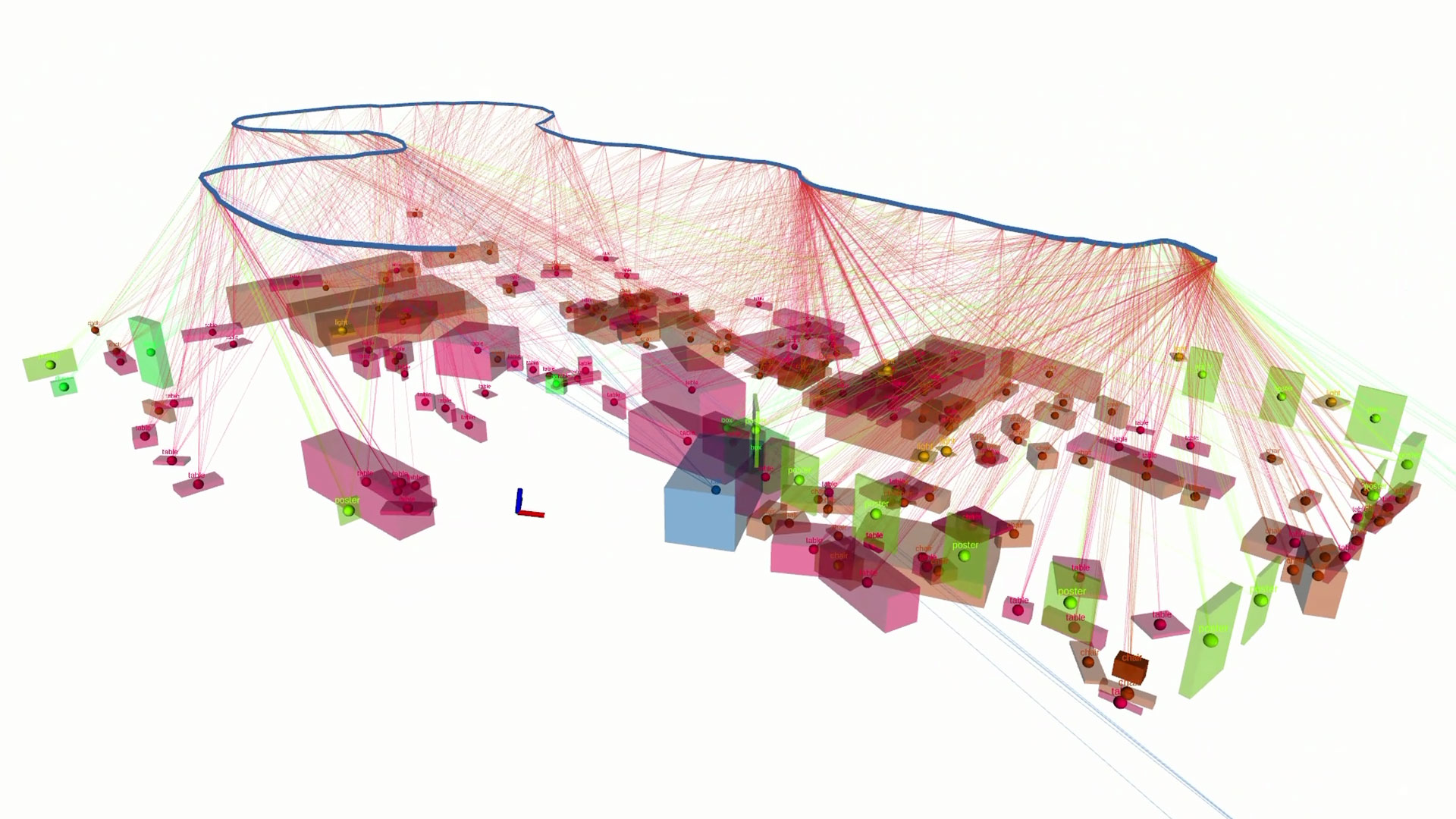
SayNav: Grounding Large Language Models to Navigation in New Environments
SayNav is a novel planning framework, that leverages human knowledge from Large Language Models (LLMs) to dynamically generate step-by-step instructions for autonomous agents to complicated navigation tasks in unknown large-scale…
Recent publications
more +-
Concepts for autonomous navigation of underground mine face haulage equipment using depth cameras
Abstract This paper describes the development of a software pipeline for autonomous navigation of underground mine haulage equipment. The approach uses depth-sensing cameras mounted on the haulage vehicle to capture…
-
Graph2Nav: 3D Object-Relation Graph Generation to Robot Navigation
We propose Graph2Nav, a real-time 3D object-relation graph generation framework, for autonomous navigation in the real world.
-
SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
We present SayNav, a new approach that leverages human knowledge from Large Language Models (LLMs) for efficient generalization to complex navigation tasks in unknown large-scale environments.
Featured publications
-
SASRA: Semantically-aware Spatio-temporal Reasoning Agent for Vision-and-Language Navigation in Continuous Environments
This paper presents a novel approach for the Vision-and-Language Navigation (VLN) task in continuous 3D environments.
-
Graph Mapper: Efficient Visual Navigation by Scene Graph Generation
We propose a method to train an autonomous agent to learn to accumulate a 3D scene graph representation of its environment by simultaneously learning to navigate through said environment.
-
MaAST: Map Attention with Semantic Transformers for Efficient Visual Navigation
Through this work, we design a novel approach that focuses on performing better or comparable to the existing learning-based solutions but under a clear time/computational budget.