No scientist or researcher can keep current with the vast number of potentially relevant journal articles and technical documents published each year in a given field. As with many problems involving overwhelming amounts of information, computers and advanced machine learning/artificial intelligence tools offer a potential solution. Text analytics can be applied to entire document sets to map the technical advances, research trends, and relationships between concepts within and across technical domains. Researchers can use these tools to identify connections, test hypotheses, and analyze what would otherwise be impossibly large datasets.

In recent years, SRI has made significant advancements in applying text analytics to understand and analyze research trends. SRI’s Copernicus platform is capable of analyzing large digital repositories of textual information to characterize documents, extract metrics, and plot the evolution of ideas and research within a specific domain of study. The platform was developed through the support of the Intelligence Advanced Research Projects Activity (IARPA) Foresight and Understanding from Scientific Exposition (FUSE) program. SRI has advanced the Copernicus platform through projects such as the Department of Energy’s (DOE) Solar Energy Evolution and Diffusion Studies (SEEDS) program. And in 2017, the Chan-Zuckerberg Initiative acquired the start-up Meta and the license to Copernicus.
SRI’s work developing the HELIOS tool for the SEEDS project serves as a representative example of how text analytics can help manage information overload. Based on the Copernicus platform, HELIOS was used to examine how research topics with solar cell research evolved over time, and to automatically extract performance metrics for solar cell conversion efficiency.
Using Text Analytics to Identify Topic Evolution
Topic modeling is a statistical tool used to discover abstract “topics” that occur in a collection of documents. By analyzing topic models over time, we can create a map of how research in a domain evolves, exploring how scientific terminology and concepts change over time as new topics emerge and old topics wane.
Temporal analysis of topic models can reveal when one topic replaces another – a phenomenon that often occurs when one technology replaces another. For example, the technology used in dye-sensitized solar cells (DSSC) shifted from aqueous approaches towards solid-state approaches in the mid-2000’s. SRI’s topic modeling highlighted the same shift.
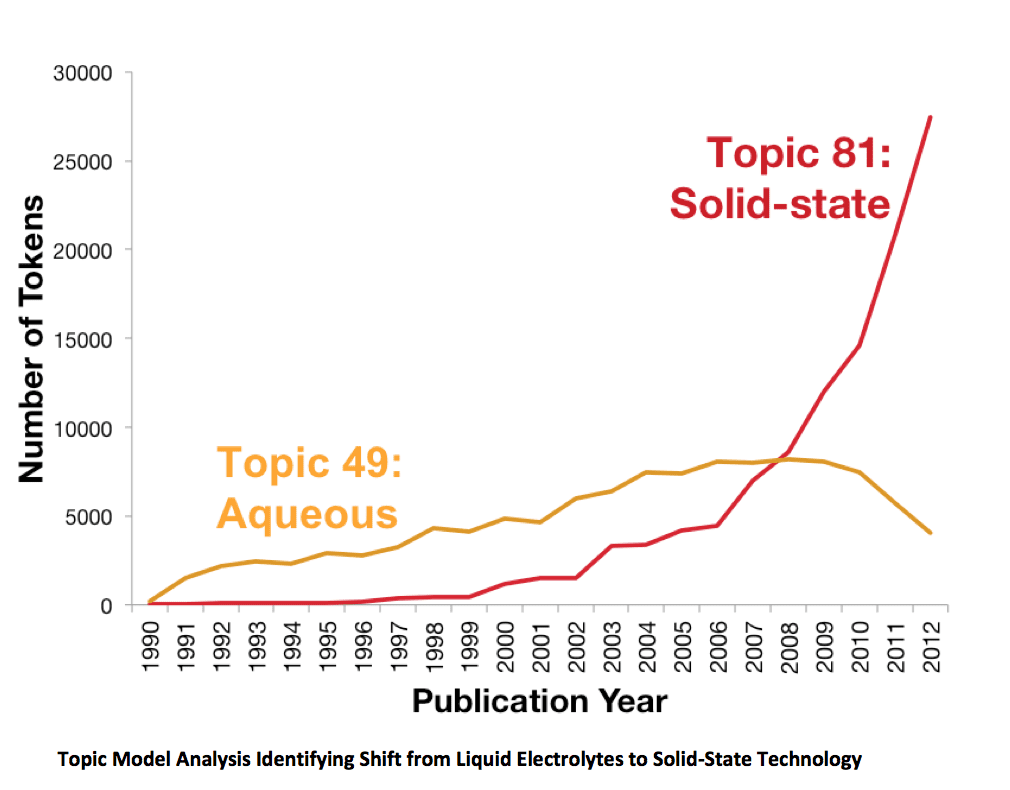
Expanding this approach to apply to an entire document set, we can explore how different topics coalesce into single topics over time, how single topics diverge, and how topics replace one another as we explore a domain.
Extracting Performance Metrics Using Text Analytics
Solar cell technologies are tracked by how efficiently they can convert light into energy. This is arguably the most important performance metric for solar cells. National Renewable Energy Laboratory (NREL) regularly publishes a graph illustrating the best research-cell efficiencies across a number of solar technologies. Currently these data are gathered manually as individual researchers submit new records to NREL. We used machine learning to train the HELIOS tool to identify and extract efficiency claims from our document set on solar cell research. Our approach replicated the efficiency trend for Cadmium-Telluride solar cells exactly, and suggests that text analytics can be used to automatically conduct this performance extraction. Manually creating this sort of table in another technology area where there is no centralized entity would be a time-consuming and onerous task, especially for non-experts.
Using AI to Enhance Human Research
Researchers tend to specialize narrowly to best keep up with the advances in their domains of study. Text analytics enables researchers to examine a vast amount of information to incorporate a larger, and more diverse, scope of research in their own work. Text analytic tools serve as a means to confirm and stress-test the conclusions of human analysts, helping them identify topics, concepts, and trends that might not otherwise have been considered.
As these automated techniques improve, they are likely to be more widely used in research, especially in areas such as policy and research planning, where non-experts are often called upon to review a wide range of scientific literature. Because these tools hold promise for identifying connections and analyzing research trends, they will be of most benefit when used by creative and curious human analysts.


