Collaborative autonomy
-

Designing better human-machine teams
SRI is discovering how AI can organize humans and machines into complex, collaborative, high-functioning units.
-

Robot teams that talk to humans
SRI scientists created a new AI-based approach to robotics that enables mobile robots to effectively communicate with each other — and with their human operators.
-
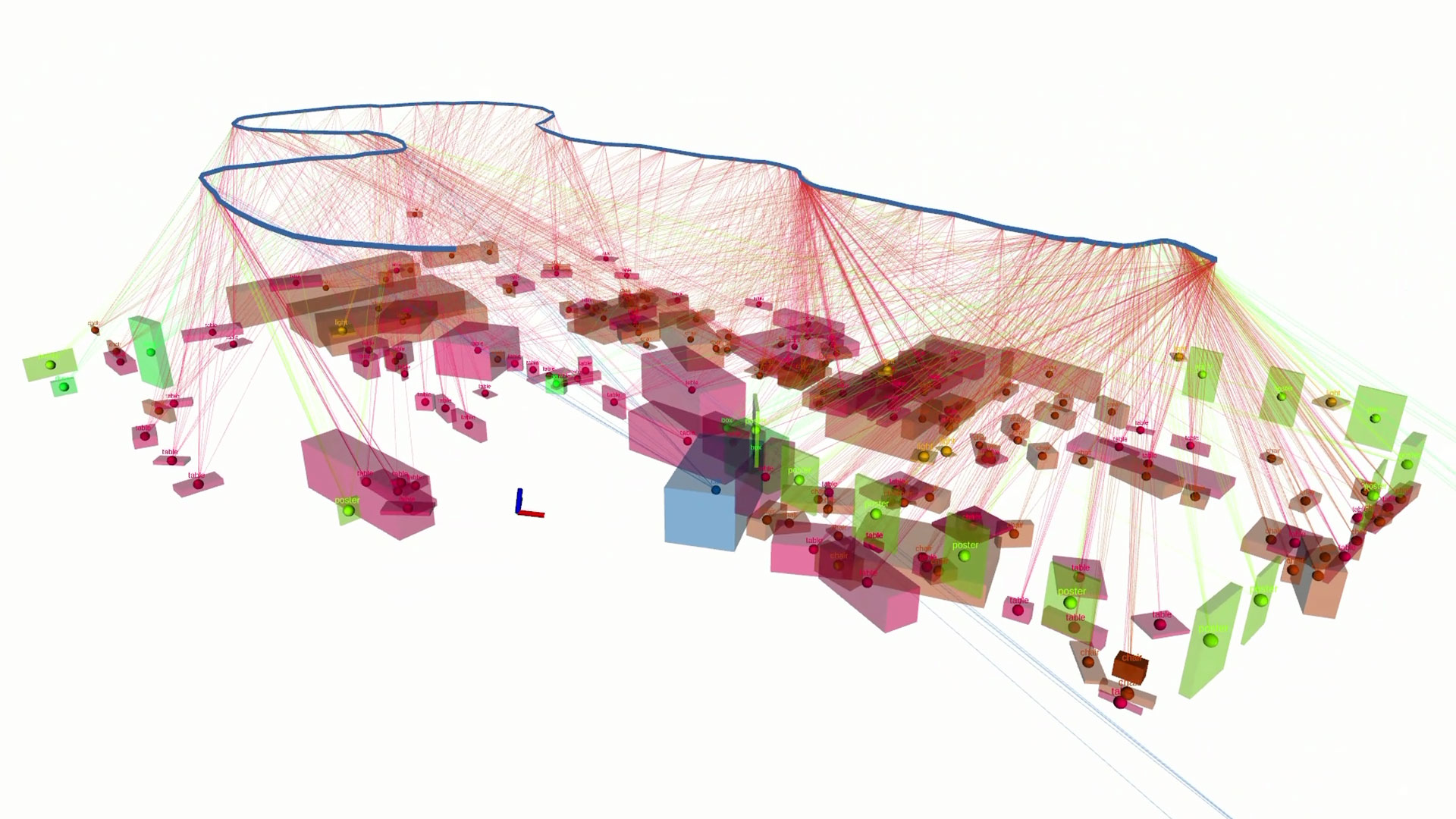
SayNav: Grounding Large Language Models to Navigation in New Environments
SayNav is a novel planning framework, that leverages human knowledge from Large Language Models (LLMs) to dynamically generate step-by-step instructions for autonomous agents to complicated navigation tasks in unknown large-scale environments. It also enables efficient generalization of learning to navigate from simulation to real novel environments.
-

Pedestrian Detection from Moving Unmanned Ground Vehicles
SRI’s vision-based systems enable safe operations of moving unmanned ground vehicles around stationary and moving people in urban/cluttered environments. Under the Navy Explosive Ordnance Disposal project, SRI has developed a real-time, fused-sensor system that significantly improves stationary and dynamic object detection, pedestrian classification, and tracking capabilities from a moving unmanned ground vehicle (UGV). The system…
-

Vision and Language Navigation
SASRA: Semantically-aware Spatio-temporal Reasoning Agent for Vision-and-Language Navigation in Continuous Environments SRI International has developed a new learning-based approach to enable the mobile robot to resemble human capabilities in semantic understanding. The robot can employ semantic scene structures to reason about the world and pay particular attention to relevant semantic landmarks to develop navigation strategies.…