Speech technology and research lab
Communicating with, and through, computer applications
The Speech Technology and Research (STAR) Laboratory brings together a multidisciplinary mix of engineers, computer scientists and linguists. Together, our experts build systems for a wide range of applications including signal processing; data indexing and mining; and computer-aided learning. SRI’s speech and language technologies allow us to interact more naturally with computing applications and provide a wealth of actionable information about our intentions, health, and emotional state.
Core technologies and applications
Real-world impact
-
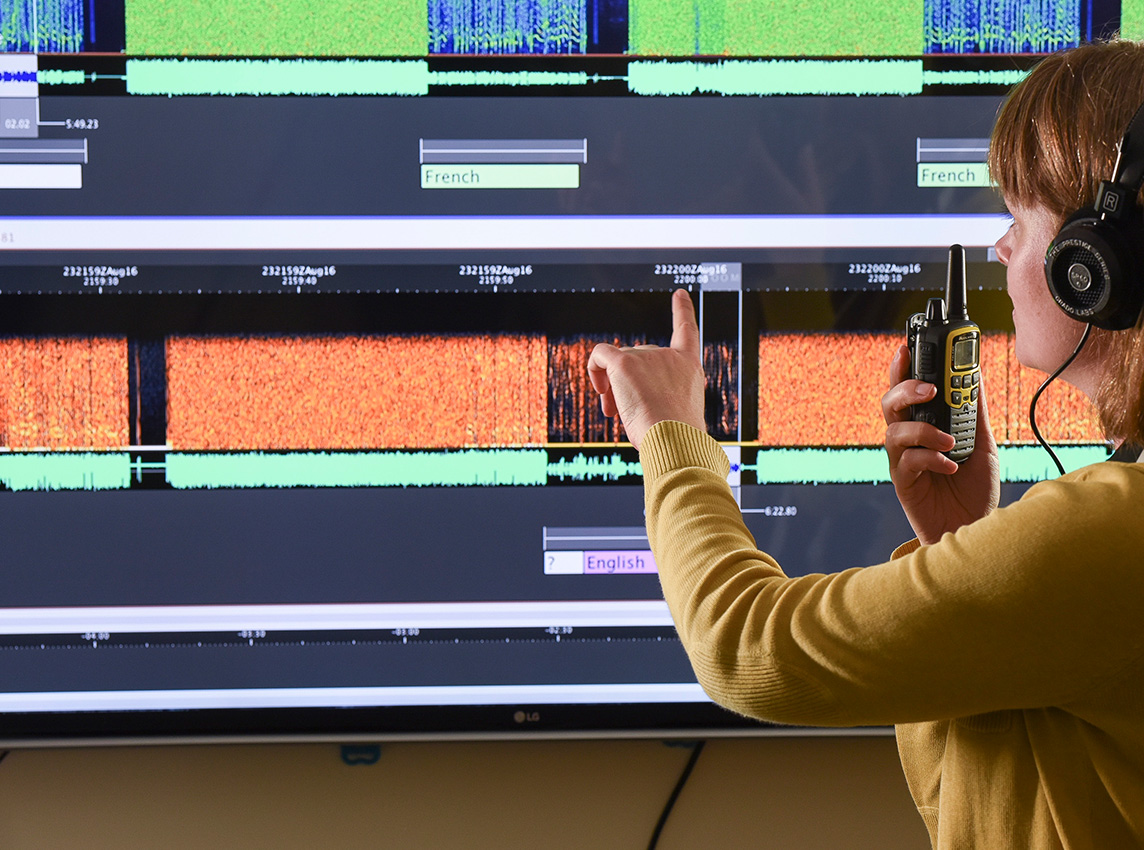
Case study: A game-changing multimedia processing platform for national defense and commercial innovation
SRI’s Open Language Interface for Voice Exploitation has become a critical tool for both government customers and next-generation AI startups.
-

What’s next in AI-based translation?
Reviewing the Apple AirPods Pro 3, The New York Times turned to SRI’s Dimitra Vergyri to unpack the significance of recent advances in translation tech.
-

SRI’s AI-driven voice analysis could help screen for mental health conditions
Researchers at SRI are developing tools to help clinicians keep a close eye on depression, PTSD, and other mental health issues.
Featured researchers
-

Dimitra Vergyri
President, Information and Computing Sciences Division; Director, Speech Technology and Research Laboratory (STAR)
-

Horacio Franco
Chief Scientist, Speech Technology and Research Laboratory
-

Aaron Lawson
Assistant Laboratory Director, Speech Technology and Research Laboratory
-

Martin Graciarena
Technical Manager, Speech Technology and Research Laboratory
-

Mitchell McLaren
Senior Computer Scientist, Speech Technology and Research Laboratory
-

Harry Bratt
Senior Computer Scientist, Speech Technology and Research Laboratory
Platforms
Publications
-
Toward Fail-Safe Speaker Recognition: Trial-Based Calibration with a Reject Option
In this work, we extend the TBC method, proposing a new similarity metric for selecting training data that results in significant gains over the one proposed in the original work.
-
Resilient Data Augmentation Approaches to Multimodal Verification in the News Domain
Building on multimodal embedding techniques, we show that data augmentation via two distinct approaches improves results: entity linking and cross-domain local similarity scaling.
-
Natural Language Access: When Reasoning Makes Sense
We argue that to use natural language effectively, we must have both a deep understanding of the subject domain and a general-purpose reasoning capability.